In this tutorial, we will learn how to count the frequency of the word in a text file using python script. This will be very helpful to find the count of duplicate words from documents(text, CSV, SQL, etc.). Also, it can be used to validate the word count from text documents. Before jumping into the code let’s start with the required python modules and pattern matching method used in this tutorial. You can download the sample text file from the link below or also you can use your own sample text file as well.
Regular Expression.
A regular expression is a sequence of characters that defines search patterns which are generally used by string searching algorithms to find and replace string, pattern matching, input validation, text count validation. Since it is a standard library module it comes with python by default so no need for any installation. You can use it by importing a standard re module.
import re
In this tutorial, we are going to use it to find the count of the distinct word from a text file. Regular Expression itself is a complex chapter so we will discuss it in another tutorial in detail.
Findall.
It is a method defined inside a regular expression module which is used to find the all matching pattern of the supplied variable.
re.findall(r’\b[a-z]{2,15}\b’, text)
This expression will return all the words which have a minimum of 2 character length to a maximum of 15 characters small letter alphabets. It won’t return the string which contains other than small letter characters [a-z], 1 character length string and more than 15 character length string as well.
Source code.
import re
frequency = {}
#Open the sample text file in read mode.
document_text = open('sample.txt', 'r')
#convert the string of the document in lowercase and assign it to text_string variable.
text = document_text.read().lower()
pattern = re.findall(r'\b[a-z]{2,15}\b', text)
for word in pattern:
count = frequency.get(word,0)
frequency[word] = count + 1
frequency_list = frequency.keys()
for words in frequency_list:
print(words, frequency[words])
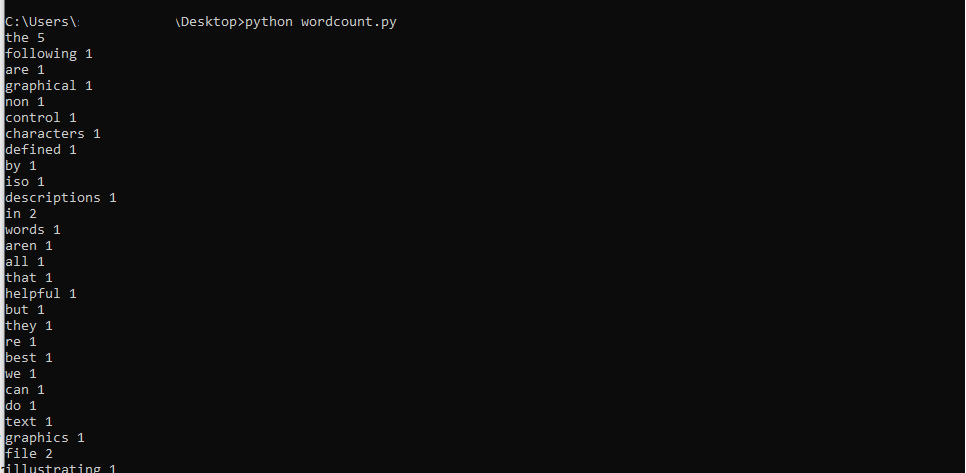
Output.